IACS Computes! 2019
IACS Computes! High School summer camp
Day 1
Day 2
Day 3
Day 4
Day 5
Day 6
Day 7
Day 8
Day 9
Literature analysis with n-grams
As you probably know from your English homework, comparing works of fiction can be a very hard and time-consuming task. It would be much nicer if we could just have the computer do all the hard work for us. But how could that work?
One simple idea is that an author’s style is represented by which words they use, and in particular which words they use most. Sequences of words are known as n-grams. A single word is known as a unigram, a pair of words as a bigram, three words as a trigram, etc. For example, the sentence
John likes Mary and Peter
contains the unigrams
John, likes, Mary, and, Peter
the bigrams
John likes, likes Mary, Mary and, and Peter
and the trigrams
John likes Mary, likes Mary and, Mary and Peter
We can also have 4-grams, 5-grams, or 127-grams. A model that is based on words or sequences of words is called an n-gram model. So if we want to analyze an author’s style in terms of their word usage, we could use a unigram model of stylistic analysis.
But does a unigram model actually work? Well, let’s put the idea to the test: we will compare three works of fiction using this technique:
- William Shakespeare’s Hamlet
- Christopher Marlowe’s The Tragical History of Dr. Faustus
- Edgar Rice Burrough’s A Princess of Mars
If we find something interesting, then unigram models might be worthwhile.
A brief remark on those works: The first two are world-famous plays, whereas the third is an early 20th century pulp novel that you might know as the basis for Disney’s 2012 box office debacle John Carter. Although the movie is better than its reputation, it still doesn’t do justice to the book, so give it a read if you are in the mood for a fun science fantasy story.
Getting the files
First we need to have the books in some digital format that we can feed into Python. Ideally, we want this to be a plaintext format, i.e. the pure text without any layout information. We do not want a pdf or doc file, as those are much harder to work with. We can use Python to download all the files from Project Gutenberg, an online platform that hosts literary works that are no longer under copyright.
To do so, we first import the library urllib.request and then use the following command:
urllib.request.urlretrieve("url_to_download", "filename_of_your_choice")
import urllib.request
urllib.request.urlretrieve("https://www.gutenberg.org/files/1524/1524-h/1524-h.htm", "hamlet.txt")
urllib.request.urlretrieve("https://www.gutenberg.org/cache/epub/811/pg811.txt", "faustus.txt")
urllib.request.urlretrieve("https://www.gutenberg.org/cache/epub/62/pg62.txt", "mars.txt")
('mars.txt', <http.client.HTTPMessage at 0x7f50f0521dd8>)
Running the code above should have put three files in the folder you are running this notebook from:
faustus.txthamlet.txtmars.txt
Open the files and have a look (e.g. if you’re using Jupyter Lab, you can open them up as new tabs). Scroll up and down a bit to get a better idea of what the files look like. Write down a list of the things that stand out to you. In particular:
- Do the files look the same, or are there major differences?
- Do the files just contain the text of the plays, or also additional information (check the top and bottom of each file carefully)?
- If we want just the words used by the protagonists of the plays, what changes do we need to made to the files?
Cleaning up the files
Analysis
You should have noticed quite a few problems with the files, only some of which we can easily fix by hand.
-
While
faustus.txtandmars.txtare fairly easy to read,hamlet.txtis cluttered with all kinds of weird code like<p>and<br/>. That’s because we downloaded a text file forfaustus.txtandmars.txt, but an HTML file forhamlet.txt. The expressions between<and>are HTML markup, which is needed to display the file in a web browser. -
All files start with information about Project Gutenberg, which we do not want.
-
All files have information at the end that is not part of the play. In
hamlet.txtandmars.txt, it’s just a disclaimer that the play is over, whereasfaustus.txtis also full of footnotes. -
In
faustus.txt, the text is often interrupted by strings like[17]. Those are references to footnotes. - For the two plays, slightly different formats are used to indicate who is speaking.
- In
hamlet.txt, names are fully capitalized and occur between the markup<p>and<br/>. Sometimes there is a dot after the name, sometimes there isn’t. - In
faustus.txt, names are fully capitalized and followed by a dot. The actual text usually starts on the same line.
- In
-
In
faustus.txt, stage instructions are indicated by indentation. Inhamlet.txt, they occur between<p class="scenedesc">and</p>. -
In
faustus.txt, all dialog is indented, but less so than the stage instructions. -
All three files contain many empty lines.
-
Both plays capitalize words at the beginning of a new line.
- In
mars.txt, Chapters are written in upper caps.
These are all problematic for us:
- We just want to be able to see which words are used in each play, and how often each word is used.
- We do not want HTML markup, information about Project Gutenberg, footnotes, or empty lines.
- We also do not want to keep track of names if they just indicate who is speaking, as we’re interested in what the characters are saying.
- We should also exclude stage instructions because those do not belong to the literary part of the play either.
Fixing all these things by hand would be a lot of work. Fortunately, we only need to delete a few things by hand, while Python can do the rest.
Clean-up
Let’s first do the manual fixes.
Carry out the fixes below, then save the modified files under new names so that they don’t get overwritten in case you redownload the files: hamlet_manual, faustus_manual, and mars_manual.
-
Open
hamlet.txtand delete the first 192 lines. That’s everything before the line<h3><b>SCENE. Elsinore.</b></h3>. -
Now go to the end of
hamlet.txtand delete everything after line 7754. That’s everything after (and including) the line with the single tag<pre>. It is the only such tag in the file, so it is easy to find with your editor’s search function. -
Open
faustus.txtand delete the first 140 lines. That’s everything up to and including the empty line right afterFROM THE QUARTO OF 1616. -
In the same file, delete everything after the line
Terminat hora diem; terminat auctor opus.Use the editor’s search function to find it quickly. -
Open
mars.txtand delete the first 235 lines. That’s everything before the line that saysCHAPTER I. -
In the same file, delete everything after the line
that I shall soon know.
We have removed quite a bit of unwanted stuff, but there’s still many problems with the formatting. The Python code below fixes all of those for us using a powerful pattern matching technique called regular expressions (also known as regex). Don’t worry for now about trying to understand how it works - regex is confusing even for those who use it often!
# Code to clean up hamlet.txt, faustus.txt, and mars.txt
# ======================================================
# import regular expressions library
import re
# define a general function for loading and writing files
def text_cleaner(filename):
"""
Open text and run required cleaning procedures.
Arguments
---------
filename: str
name of file without extension (for instance .txt)
"""
# Step 1: load file and store it as variable "text"
with open(filename + "_manual.txt", mode="r", encoding='utf-8-sig') as text:
# Step 2: create a new file to save cleaned up version
with open(filename + "_clean.txt", mode="w", encoding='utf-8') as cleaned:
# Step 3: clean each line and write to clean-up file
for line in text:
# cleaning
line = line_cleaner(filename, line)
# write line if it isn't empty
if line != "\n":
cleaned.write(line)
# define a function that cleans each line for each text
def line_cleaner(filename, line):
"""clean line for hamlet, faustus, and mars"""
# hamlet-specific cleaning
if filename == "hamlet":
# 1. remove all headers
line = re.sub(r'<h[0-9].*', r'', line)
# 2. remove speaker information
# (identified by html tags)
line = re.sub(r'<p[^>]*>[A-Z\. ]<br/>', r'', line)
# 3. remove html tags
line = re.sub(r'<[^>]*>', r'', line)
# 4. remove anything after [ or before ]
line = re.sub(r'\[[^\]]*', r'', line)
line = re.sub(r'[^\[]*\]', r'', line)
# 5. replace special html codes by characters
line = re.sub(r'&[rl]squo;', r"'", line)
line = re.sub(r'—', r" --- ", line)
line = re.sub(r"&c[\.,]", r"&", line)
# faustus-specific cleaning
elif filename == "faustus":
# 1. remove stage information
# (anything after 10 spaces)
line = re.sub(r'(\s){10}.*', r'', line)
# 2. remove speaker information
# (any word in upper caps followed by space or dot)
line = re.sub(r'[A-Z]{2,}[\s\.]', r'', line)
# 3. remove anything between square brackets
line = re.sub(r'\[[^\]]*\]', r'', line)
# 4. remove sentence initial spaces
line = re.sub(r'^\s+', r'', line)
# mars-specific cleaning
elif filename == "mars":
# 1. delete CHAPTER I
# (must be done like this because Roman 1 looks like English I)
line = re.sub('CHAPTER I', '', line)
# 2. remove any word in upper caps
line = re.sub(r'[A-Z]{2,}[\s\.]', r'', line)
# 3. remove anything after [ or before ]
line = re.sub(r'\[[^\]]*', r'', line)
line = re.sub(r'[^\[]*\]', r'', line)
else:
raise Exception("No cleaning profile exists for this file")
# remove multiple spaces that might be left after clean up
line = re.sub(r'\ +', ' ', line)
# return cleaned up line with everything in lower case
return line.lower()
# do the actual cleaning
for filename in ["hamlet", "faustus", "mars"]:
text_cleaner(filename)
After running the code, open the files faustus_clean.txt, hamlet_clean.txt, and mars_clean.txt.
All the unwanted annotations, markup and stage instructions are gone, and we have a much cleaner file now.
Also note that now all words are lowercase, including proper names.
That is a feature, not a bug: but and But are the same word, so we do not want to count them separately.
That the texts now talk about hamlet, faustus, and carter is not much of an issue since proper names are rarely identical to existing words.
Why do we bother with this step? We have to make sure that our data is a clean as possible in order to do good analysis. Now we have nice clean files, we can get started on our analysis!
Tokenization
Remember that we are interested in determining which words each author uses, and how often they do so. As far as Python is concerned, our text files are just a very long string of random characters. Python has no understanding of what a word is, so it cannot count words without our help. What we need to do is to tell Python how it can convert a string into a list of words. For example, the string
John likes John, Bill's mother, and Sue.
should be converted to the list
["John", "likes", "John", ",", "Bill", "'s", "mother", ",", "and", "Sue", "."]
Notice that the list may contain duplicates — reading the list from left to right must give us the original sentence without any omissions. Also, punctuation is still included, but each punctuation mark is treated like an individual word.
This process of converting a string to a list is called tokenization. A tokenizer is a function that reads in a string and returns the corresponding list. So your first job is to write a function that reads in a whole play as a string and then returns the tokenized list.
# A few hints for writing a tokenizer:
#
# 1) You need to load the file first obviously;
# but I suggest that you also take a look at the corresponding strings;
# you will encounter a few surprises, in particular many instances of \n;
# each \n marks the end of a line
#
# 2) For the purpose of tokenization, the following things are words:
# A. punctuation symbols (! ? . , ; :)
# B. a hyphen (-) if it is preceded by whitespace; but in words like laurel-bough, the - is not a word
# C. 's, both as a possessive marker (John's mother) and as a shortened form of is (it's, there's)
# D. any string of characters between whitespace or punctuation symbols
# E. whitespace refers to a space, but also to the special characters \t (tab) and \n (new line)
#
# 3) I suggest you iterate over the positions in the string with a for-loop.
# Save the last position that was a punctuation symbol or whitespace.
# If you encounter another punctuation symbol or whitespace,
# the string between this current position and the previously saved one is a word.
# But careful: the apostrophe complicates things a bit.
#
# Alternatively, you can experiment with Python's .split method for strings,
# or use the function re.findall of the re library. The latter is very useful
# if we only care about words in the sense of D above, but is clunky for the
# other cases.
#
# Extra Challenge: The English apostrophe also shows up in contractions of will ('ll) and not (n't).
# Adapt your code so that it tokenizes "I'll" as "I will", "hasn't" as "has not", and similarly for related instances.
# The quality of your original solution shows in how easily it can be adapted to these new problems.
punctuation = ["!", "?", ".", ",", ";", ":"]
whitespace = [" ", "\n", "\t"]
def tokenizer(filename):
"""tokenize text given by filename"""
# some magic happens here
return tokens
hamlet = tokenizer("hamlet_clean.txt")
faustus = tokenizer("faustus_clean.txt")
mars = tokenizer("mars_clean.txt")
Converting the tokenized list to a dictionary
A tokenized list is nice, but not enough. We also want to know how often each word is used. We can do this with a dictionary where the keys are words and the values indicate how often the word occurs in the tokenized list. For example, the list
["John", "likes", "John", ",", "Bill", "'s", "mother", ",", "and", "Sue", "."]
should be converted to the dictionary
{"John": 2, "likes": 1, ",": 2, "Bill": 1, "'s": 1, "mother": 1, "and": 1, "Sue": 1, ".": 1}
# Write a function that converts the tokenized lists to dictionaries
#
# Pro-tip: Python has a special subtype of dictionaries called Counters, which are perfect for this task.
# So if you want, you can use a Counter instead of a dictionary.
# Google around a bit to see how they work.
def ngram_counter(tokens):
# some magic happens here
return counts
hamlet_counts = ngram_counter(hamlet)
faustus_counts = ngram_counter(faustus)
mars_counts = ngram_counter(mars)
Analyzing the dictionaries
Our first attempt…
Alright, now we finally have word counts for both plays. But what are we supposed to do with them? The dictionaries are way too large to compare by hand. Well, we could first compare the ten most common words in each dictionary.
# Here's a nice helper function
def dict_to_ordered_list(dictionary):
"""convert dictionary to list of keys, ordered by decreasing value"""
# key=dictionary.get uses the values for sorting
# reverse=True sorts the list in descending order rather than ascending
return sorted(dictionary, key=dictionary.get, reverse=True)
# Your turn! Use the helper function to look at the ten most common words in each play.
# Extra task: if you used a counter, there's already a built-in method for this.
# What is it?
…is a failure
Well that output isn’t very helpful, it’s all just punctuation and useless words like a and the and to. But that’s actually expected. Punctuation is very common in written text. And then there is Zipf’s law: ranking words by their frequency, the n-th word will have a relative frequency of 1/n. So the most common word is twice as frequent as the second most common one, three times more frequent than the third most common one, and so on. As a result, a handful of words make up over 50% of all words in a text.
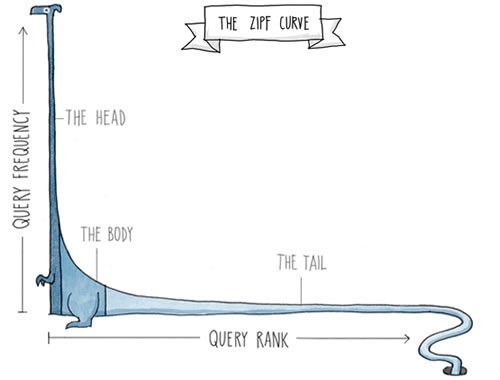
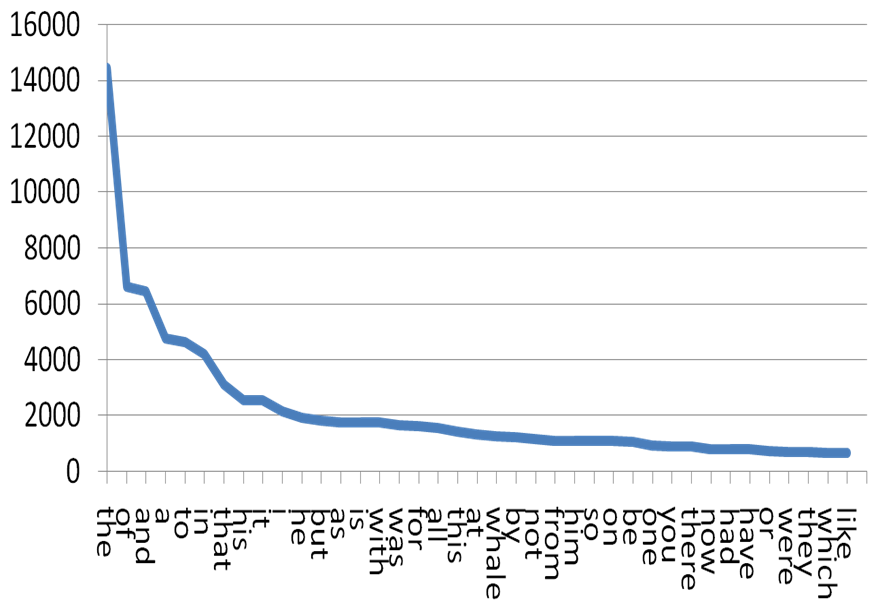
Looking at the ten most common words in each play can’t reveal much because Zipf’s law already tells us that those words won’t be interesting. If we want to find anything of interest, we have to ignore punctuation and all these common but uninteresting words, which are also called stop words.
# Okay, time to deal with stop words:
#
# 1) Download the file from
# https://raw.githubusercontent.com/stanfordnlp/CoreNLP/master/data/edu/stanford/nlp/patterns/surface/stopwords.txt
# You can use Python's urllib.request.urlretrieve function for this
# 2) Each line of the file contains a stop word.
# Read in the file and convert it to a list of stop words.
# 3) Use this list to look at the ten most common words in each play that are not stop words.
# If necessary, you can add stop words beyond what is provided in the list to filter out additional words.
# 4) Don't forget to also filter out all punctuation.
#
#
# Pro-tip: Step 3 can be done with a single line of code using a Python list comprehension;
# if you're curious, ask your tutor or google it
Plotting the data
Now we have a rough idea which words are the most common in each play, and a few differences already show up at this point. In particular, it should be pretty easy for you to tell for each list which book it was built from. Try experimenting with larger values and whether they make the lists more similar or more distinct.
But we could look at much more than just the relative ranking of words. Maybe one author is much less creative in their choice of words than the other. Then we would expect that the uncreative author uses the same words over and over, whereas the creative one avoids repetitions.
We can rephrase this idea as a problem of relative frequency: how frequent are words relative to other words in the text? This can be visualized in a graph where words are placed along the x-axis and the y-axis indicates for each word how often it occurs. When the words are ordered by frequency, a creative author should produce a graph with a very long tail — that is to say, there’s many, many words with very low frequency. An uncreative author, on the other hand, should have a small stock of words that occur over and over and a comparatively shorter tail.
We can use Python’s matplotlib package to produce such graphs for us.
Matplotlib will take the dictionaries as input with keys for the x-axis and values for the y-axis.
But recall that our dictionaries still contain the unwanted stop words and punctuation.
We need to fix this first.
def dict_without_unwanted_words(dictionary, list_of_crud):
"""remove unwanted entries from dictionary"""
# some magic happens here
return clean_dictionary
hamlet_dict = dict_without_unwanted_words(hamlet_counts, punctuation + stopwords)
faustus_dict = dict_without_unwanted_words(faustus_counts, punctuation + stopwords)
mars_dict = dict_without_unwanted_words(mars_counts, punctuation + stopwords)
Now we can finally look at the graphs for Hamlet, Dr. Faustus, and Princess of Mars.
%matplotlib inline
figsize(20, 10)
# the lines above are needed for Jupyter to display the plots in your browser:
# do not remove them
# import relevant matplotlib code
import matplotlib.pyplot as plt
# a little bit of preprocessing so that the data is ordered by frequency
def plot_preprocess(dictionary, n):
"""format data for plotting n most common items"""
sorted_list = sorted(dictionary.items(), key=lambda x: x[1], reverse=True)[:n]
words, counts = zip(*sorted_list)
return words, counts
for dictionary in [hamlet_dict, faustus_dict, mars_dict]:
# you can change the max words value to look at more or fewer words in one plot
max_words = 100
words = plot_preprocess(dictionary, max_words)[0]
counts = plot_preprocess(dictionary, max_words)[1]
# put your code for plotting the data here
Do these graphs tell us anything about whether Shakespeare or Marlowe was the more creative writer? How does the pulp author Edgar Rice Burrough fare? Are these results surprising to you, or is this all expected given Zipf’s law? Or did we make mistakes in our analysis? If so, what changes should we make?
Moving to bigrams and trigrams
One could argue that just counting words is not an adequate representation of a writer’s style. Often the important thing is not so much which words an author uses, but how they use them. While a sophisicated analysis of writing style is a very difficult affair, our unigram approach can be easily tweaked to move beyond words.
One way of formalizing the idea of creative word usage is to look in which order words appear. That is very easy with n-grams. From the list of tokenized words, one can easily construct a list of n-grams. For example, the list
["John", "likes", "John", ",", "Bill", "'s", "mother", ",", "and", "Sue", "."]
could be converted to a list of bigrams.
[("John", "likes"),
("likes", "John"),
("John", ","),
(",", "Bill"),
("Bill", "'s"),
("'s", "mother"),
(",", "and"),
("and", "Sue"),
("Sue", ".")]
Note that we treat n-grams as tuples in Python.
def list_to_ngrams(tokenized_list, n):
"""convert tokenized list to list of n-grams (n = 2 or greater)"""
# some magic happens here
return ngram_list
hamlet_bigrams = list_to_ngrams(hamlet, 2)
faustus_bigrams = list_to_ngrams(faustus, 2)
mars_bigrams = list_to_ngrams(mars, 2)
Now we can repeat our previous analysis using bigrams or trigrams instead of just words. (We could also look at 4-grams or 5-grams, but that is a lot harder to compute and we just don’t have enough data to use such large n-grams effectively — however, the 4-gram counts for Hamlet are somewhat surprising compared to the other works.) So let’s see if the step from words to bigrams/trigrams changes things.
# Compute dictionaries to keep track of how often each n-gram occurs.
# You do not need to worry about stop words in this case.
# Remember that you already have a function for this task.
# Plot the data with matplotlib and see if the frequencies change a lot.
So now it is time for you to formulate a final verdict:
- Has the move to bigrams/trigrams changed the results a lot?
- Do those results reflect your personal expectations about the author’s writing styles?
- Depending on your answer, how much would you trust such quantiative approaches to evaluating writing style?
- Would it surprise you to hear that more and more colleges across the US are relying on software which uses n-gram analysis as part of its criteria to grade student essays? Would you want your own essay to be graded this way?